A Fast Algorithm For Deep Belief Net [논문]
저자 : Geoffrey E. Hinton and Simon Osindero
Abstract
- hidden layer가 많고 densely-connected belief nets에서 추론을 어렵게 만드는 설명 효과를 제거하기 위해 “complementary priors”를 사용하는 방법을 보여준다.
- “complementary priors”를 사용하면 두 layer가 undirected associative memory를 형성하는 경우, 더 빠르고 greedy한 알고리즘을 도출할 수 있다.
DBN(Deep Belief Network) & RBM(Restricted Boltzmann Machine)
RBM
- RBM은 Generative Model로 ANN, DNN, CNN, RNN 과 같은 Deterministic Model들과 다른 목표를 가짐.
- Deterministic Model들이 타겟과 가설 간의 차이를 줄여서 오차를 줄이는 것이 목표라고 한다면, Generative Model들의 목표는 확률밀도함수를 모델링하는 것이다.
- Boltzmann Machine이 가정한 것은 “우리가 보고 있는 것들 외에도 보이지 않는 요소들까지 잘 포함시켜 학습할 수 있다면 확률분포를 좀 더 정확하게 알 수 있지 않을까?”라는 것이다.
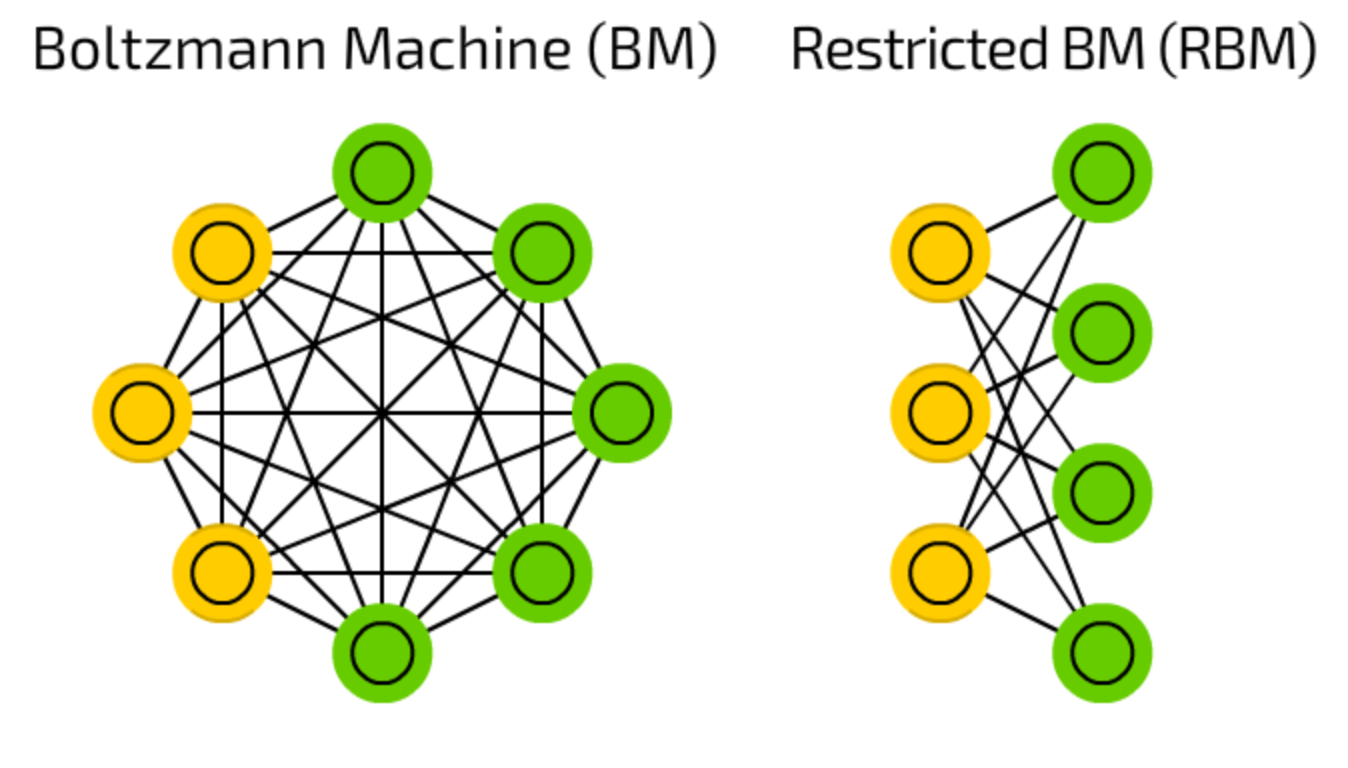
- 노란색은 hidden unit, 초록색은 visible unit.
- RBM은 Boltzmann Machine에서부터 파생되어 나온 것으로 visible unit과 hidden unit에는 내부적인 연결이 없고, visible unit과 hidden unit 간의 연결만이 남아있는 형태이다.
- 우선은 visible, hidden layer의 node 간의 내부적인 연결이 없어진 것은 사건 간의 독립성을 가정함으로써 확률분포의 결합을 쉽게 표현하기 위해서이다.
- 또, visible layer와 hidden layer만을 연결해줌으로써 visible layer의 데이터가 주어졌을 때 hidden layer의 데이터를 계산할 수 있도록 하거나 혹은 hidden layer의 데이터가 주어졌을 때 visible layer의 데이터를 계산할 수 있도록 하는 ‘조건부 확률’을 계산할 수 있게 하는 것이다. \(즉, p(h,v) 는 계산하기 어렵지만, p(h|v) 나 p(v|h) 는 계산이 수월하기 때문이다.\)
- 더 자세한 내용 : https://angeloyeo.github.io/2020/10/02/RBM.html
DBN
- 입력층과 은닉층으로 구성된 RBM을 블록처럼 여러 층으로 쌓인 형태로 연결된 신경망
- 피드포워드 신경망에서 경사감소 소멸문제를 해결하기 위해 등장
- 특징
- 비지도학습
- 데이터가 충분하지 않을 때 유용
- 겹층 RBM

1. Introduction
- 데이터 벡터가 주어졌을 때 숨겨진 활동의 조건부 분포를 추론하기 어렵기 때문에 hidden layer가 많은 조밀하게 연결된 방향성 신뢰 네트워크에서는 학습이 어렵다.
- Variational methods : 실제 조건부 분포에 대한 근사치를 사용. but, 사전 분포가 독립성을 가정하는 가장 깊은 hidden layer에서는 근사치가 좋지 않을 수 있다.
- Variational learning : 모든 매개변수를 학습해야 하며 매개변수 수가 증가함에 따라 학습 시간 규모가 제대로 설정되지 않을 수 있다.
- 그래서 이 논문에서는 새로운 모델을 설명하려고 함.
- 상위 두 개의 hidden layer가 undirected associative memory를 형성.
- 나머지 hidden layer가 directed acyclic graph를 형성.(이미지의 픽셀과 같은 관찰 가능한 변수로 변환)
- 이 모델의 특징
- 수백만의 매개변수와 hidden layer가 있어도 좋은 매개변수 세트를 빠르게 찾을 수 있는 빠르고 greedy한 algorithm이 있다.
- 비지도 방식이지만, 레이블과 데이터를 모드 생성하는 모델을 학습해 레이블이 지정된 데이터에도 적용할 수 있다.
- MNIST에서 우수한 성과가 있는 미세 조정 알고리즘이 있다.
- 생성모델을 사용하면 깊은 hidden layer의 분산 표현을 쉽게 해석할 수 있다.
- 지각을 형성하는데 필요한 추론은 빠르고 정확하다.
- 학습 알고리즘은 지역적으로, 시냅스 강도 조정은 시냅스 전, 후의 상태에만 의존한다.
- 통신이 간단하다. 뉴런은 확률론적 이진 상태만 전달하면 된다.
- 이후 섹션에 대해 소개함.
- section 2
- 지향 모델에서 추론을 어렵게 만드는 보완적 사전 개념(idea of complementary prior)을 소개한다.
- 상호보완적인 사전확률을 갖는 direct belief network의 예가 제시됨.
- section 3
- RBM와 가중치가 묶인 무한 directed network간의 동등성을 보여준다.
- section 4
- 한번에 한 레이어씩 다층 지향 네트워크를 구성하기 위한 빠르고 greedy한 알고리즘을 소개한다.
- variational bound를 사용하면 각 새로운 레이터가 추가될 때 전체 생성 모델이 향상된다는 것을 알 수 있다.
- greedy 알고리즘은 동일한 “약한” 학습기를 반복적으로 사용하는 부스팅과 어느 정도 유사, 다음 단계에서 새로운 것을 학습할 수 있도록 각 데이터 벡터에 다시 가중치를 부여하는 대신 이를 다시 나타냄.(?)
- Deep Directed Net을 구성하는 데 사용되는 “약한” 학습기는 그 자체가 undirected graphical 모델임.(?)
- section 5
- Fast Greedy 알고리즘에 의해 생성된 가중치가 up-down 알고리즘을 사용해 미세 조정될 수 있는 방법을 보여준다.
- section 6
- MNIST에서 성능 비교
- support vector machines에서 성능 비교
- section 7
- 시각적 입력 제약 없이 네트워크가 실행될 때 네트워크가 어떻게 동작하는지 설명한다.
- 이 논문에서는 확률론적 이진 변수로 구성된 네트워크를 고려할 것이지만 변수의 로그 확률이 직접 연결된 이웃 상태의 추가 함수인 다른 모델로 아이디어를 일반화할 수 있다고 한다.
2. Complementary priors
- Figure 2(Explaining away효과)
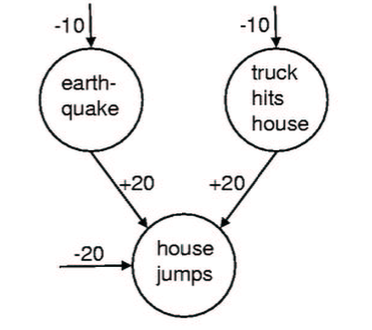
- C : 암에 걸림, H : 두통 있음, B : 멍이 듦.
- \(P(C|H)\) : 두통이 있을 때 암에 걸렸을 확률 = 0.5525
- \(P(C|H, B)\) : 두통과 멍이 있을 때 암에 결렸을 확률 = 0.112
- 이 상황에서 두통이 있으면 암에 걸렸을 확률이 55.25%이다. 그런데 거울을 보고 멍이 들었음을 알게 되었다면 암에 걸렸을 확률이 11.2%로 감소한다.
- 멍이 들었다.(B)라는 사건은 두통이 ‘암’ 이 아니라 ‘싸움’이라는 또 다른 원인으로 인해 발생했을 수 있다는 사실을 설명하기 때문이다.
- 이와 같이 Explaining away 효과가 발생할 경우 서로 독립인 변수 ‘싸움’과 ‘암’이 서로 영향을 미치기 때문에 추론이 어려워진다.
- directed belief nets에서 Explaining away 현상은 추론을 어렵게 만든다.
- 조밀하게 연결된 네트워크에서 hidden variable에 대한 posterior distribution(사후 분포)는 혼합 모델이나 additive Gaussian noise가 있는 선형 모델을 제외하고는 다루기 어렵다.
- MCMC(Markov Chain Monte Carlo)방법을 사용해 후방에서 샘플링할 수 있지만 시간이 오래 걸린다.
- MCMC(Markov Chain Monte Carlo) :
- Markov Chain을 이용한 Monte Carlo 방법.
- Monte Carlo : 수식만으로는 계산하기 어려운 문제가 있을 때 랜덤 샘플을 얻은 뒤 그 랜덤 샘플을 이용해서 함수의 값을 확률적으로 계산하는 방법이다.
- Markov Chain : 미래 확률이 과거 확률에 독립이며 오로지 직전 시점의 확률에만 의존한다는 것이 핵심이다. 즉, 한 상태에서 다른 상태로의 전이(transition)은 그동안의 전이 확률(Transition Probability)을 필요로 하지 않고 바로 직전의 전이 확률로 추정할 수 있다는 얘기이다.
- MCMC : MCMC는 우리가 샘플을 얻고자 하는 목표 분포인 Stationary distribution으로부터 랜덤 샘플을 얻는 방법
- https://m.blog.naver.com/jinis_stat/221687056797
- MCMC(Markov Chain Monte Carlo) :
-
Variational methods(Neal and Hinton, 1998)은 실제 사후를 근사화하며 훈련 데이터의 로그 확률에 대한 하한을 향상시키는데 사용할 수 있다. hidden state에 대한 추론이 잘못 수행된 경우에도 학습이 변이 범위를 개선한다는 장점이 있지만, hidden variable이 있는 모델에서도 설명을 완전히 제거하는 방법을 찾는 것이 낫다. 그런데 이는 불가능하다는 것이 널리 알려져 있다.
- Logistic belief net :
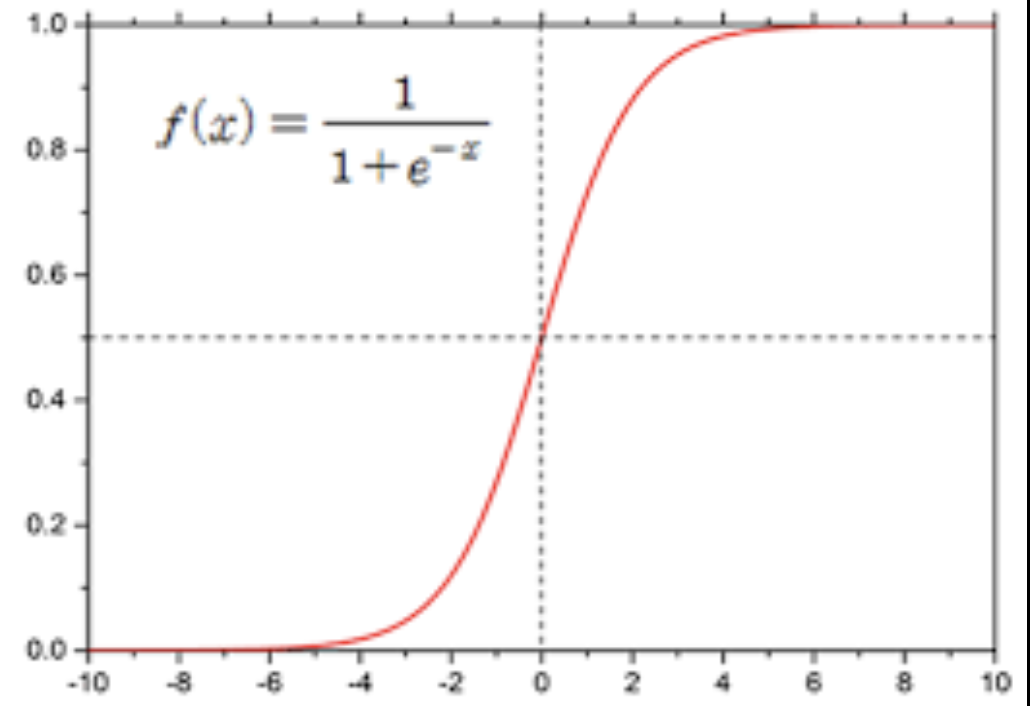
- 위 그래프는 logistic function. Logistic belief net은 logistic함수를 기반으로 한 확률적 그래픽 모델.
- bi : i의 편향, wij : i에서 j로의 가중치, i:해당노드, j:부모노드
- 노드 i가 켜질(turn on) 확률은 위 수식처럼 부모 노드 j의 켜짐 여부와 연결 가중치를 이용한 함수로 표현된다.
- 만약 logistic belief net이 하나의 은닉층만을 가진다면 은닉 노드들이 서로 독립적으로 선택되기 때문에 prior distribution이 독립 분포로 표현이 가능.
- 하지만 posterior distribution은 비독립적인데, 이는 데이터로부터의 likelihood 로 인해 생긴다.
- 연구진은 별도의 은닉층을 추가해 이 likelihood와 완전히 정반대의 상관관계를 갖는 complementary prior를 생성함으로써 첫번째 은닉층에서 발생하는 explaining away 효과를 제거할 수 있음을 보였다.
- 이후 likelihood와 prior의 곱으로 결합 분포를 구하고, 이를 normalization constant로 나누어 posterior를 독립 분포로 표현할 수 있다
- Complementary prior가 항상 존재한다고 확신할 수는 없지만, 다음 항목에서 소개하듯이 모든 은닉층에서 짝지어진 가중치들이 complementary prior를 생성하는 무한한 logistic belief net의 간단한 예시가 있음.
Figure 3
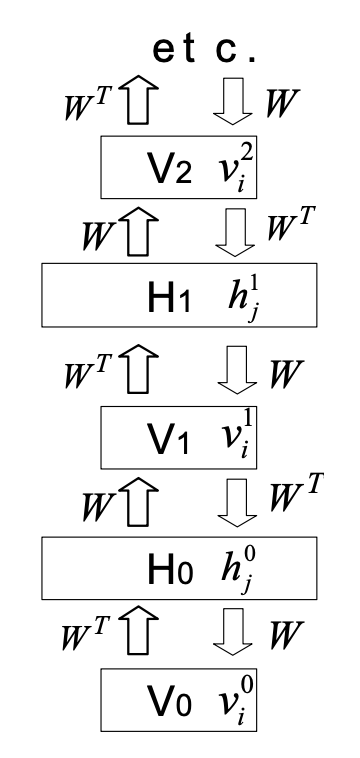
- downward : generative model.
- upward : 모델의 일부가 아님. V를 고정할 때, 사후 분포로부터 샘플을 추론하는데 사용되는 매개변수.
Appendix A : Complementary Priors
General complementarity
- x : 관찰 가능한 변수, y : hidden 변수. 에 대한 분포를 생각할 때,
- 주어진 우도 함수 \(P(x|y)\) 에 대해 대응하는 상보적(complementary) 사전 분포는 \(P(y)\) 로 정의됨. (이하 베이즈 정리 사용됨)
- \(P(y|x)\) : 사후 분포
- 이에 대한 결합 분포 \(P(x, y) = P(x|y)P(y)\) .
- \(P(y|x) = \frac{P(x|y)P(y)}{P(x)}\) . (조건부확률에 의해)
- \(P(y|x) \propto P(x|y)P(y)\) .
- 1,2,3에 의해 결합분포(\(P(x, y)\))는 우도 함수(\(P(y|x)\))와 prior(\(P(x)\))의 곱으로 표현됨.
- 결합분포(\(P(x, y)\))와 우도 함수(\(P(y|x)\))는 종속적.
- 다른 방식으로 \(P(y|x)\) 를 표현 가능.
- \(P(y|x) =\Pi_{j}P(y_{j}|x)\) .
- 이렇게 표현하면 독립적으로 \(P(y|x)\) 사용 가능.
- 주의할 점 : 가능한 모든 함수형태가 보완적 사전확률을 허용하는 것은 아님.
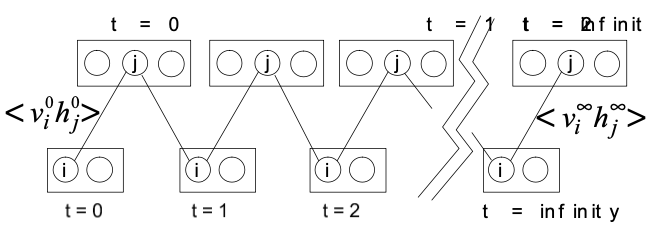
2.1 An infinite directed model with tied weights
- Figure 3의 모델은 무한히 깊은 은닉층에서 무작위 구성으로 시작해, 활성화된 부모 노드가 베르누이 분포를 따라 특정 자식 노드를 활성화시키는 top-down 방식으로 데이터를 생성해낸다.
- 이 모델은 다른 direct network와는 다르게 가시층(\(V_{0}\))의 데이터 벡터(\(v^{0}_{i}\))로부터 시작해, 전치 가중치 행렬(\(W^{T}\))을 이용해 각 은닉층의 독립 분포를 차례대로 유추함으로써 모든 은닉층의 실제 posterior를 구할 수 있다.
- 이제 실제 posterior로부터 샘플을 만들어내 그것이 데이터와 얼마나 다른지를 계산할 수 있기 때문에 데이터 \(V^{0}\) 로그 확률의 미분값을 계산할 수 있다.
- 먼저 \(w^{00}_{ij}\) 에 대한 미분값을 구하면 다음과 같다.
- \(w^{00}{ij}\) : 은닉층 \(H{0}\) 의 j 유닛과 가시층 \(V_{0}\)의 i 유닛 간의 가중치
- < … > 는 샘플랭된 값들의 평균을 의미, \(\hat{v}^{0}{i}\) 는 가시 벡터 \(v^{0}{i}\) 가 샘플링된 은닉층으로부터 재생성되었을때 유닛 i가 켜져 있을 확률을 뜻한다.
- 만약 \(\hat{v}^{0}{i}\) 과 \(v^{0}{i}\) 가 같다면 샘플링된 은닉층으로부터 실제 가시 벡터를 완벽하게 재생성할 수 있다는 것을 뜻하며 이를 위한 방향으로 모델이 학습된다.
- 그런데 이때, 첫번째 은닉층 \(H_{0}\) 로부터 \(\hat{v}^{0}{i}\)를 만들어내는 것은 첫번째 은닉층 \(H{0}\) 로부터 두번째 가시층 \(V_{1}\)을 통해 두번째 은닉층 \(H_{1}\)의 사후 분포를 계산하는 것과 완벽히 동일한 과정이다.
- 따라서 위 수식은 아래와 같이 바꿀 수 있다.
- 위와 같은 수식 변화에 있어 \(v^{0}{i}\)가 \(h^{0}{j}\) 에 전제를 둔 확률이기 때문에 \(h^{0}{j}\)에 대한 \(v^{1}{i}\)의 비독립성은 문제가 되지 않는다.
- 가중치는 같은 \(w_{ij}\)가 여러번 중복되어 사용되기 때문에 총 미분값은 아래와 같이 모든 층 간의 가중치 미분값들의 총합으로 표현된다.
- 이 식을 풀어 쓰면, 가장 처음과 마지막 항을 제외하고 서로 상쇄되어 없어지고 이는 볼츠만 머신 수식과 같아진다.
Restricted Boltzmann machines and contrastive divergence learning
Figure 4 : alternating Gibbs 샘플링을 사용하는 Markov Chain
Gibbs Sampling
- MCMC Algorithm의 특별한 방법 중 하나.
- 먼저 확률변수 x를 d개의 요소로 분해할 수 있다고 가정해 보자.
- \(x = {x_{1}, x_{2}, … , x_{d}}\)
- 이때, 깁스 샘플러에서 각 요소는 1. 무작위(randomly) 또는 2. 체계적(systematically)으로 선택되며, 각 샘플은 target density f(x)의 full conditional function에서 새로운 표본으로 업데이트 된다.
- 만약 x의 현재 반복 상태가 아래와 같이 주어지면 Gibbs sampler는 다음을 반복해서 Markov Chain을 형성.
- Systematic-scan
- 여기서 각각의 conditional distribution은 모두 closed form으로 Gibbs sampling에서 d개의 conditional distribution은 모두 우리가 알고 있는 standard한 분포이다.(Normal, Gamm 등)
- Gibbs의 장점
- 3차원을 넘어가면 시각화 할 수가 없는데 깁스 샘플링을 통해 고차원의 문제를 1차원의 문제로 바꿔 해결할 수 있다.
- RBM에서 데이터를 생성하려면 레이어 중 하나에서 무작위 상태로 시작한 다음 교대로 Gibbs 샘플링을 수행할 수 있다.
- Figure 4에서 처럼 한 레이어의 모든 유닛은 레이어에 있는 유닛의 현재 상태를 고려해 병렬로 업데이트 된다.
- 이는 가중치가 묶인 infinite belief net에서 데이터를 생성하는 방법과 정확히 동일함.
- RBM에서 최대 likelihood 학습을 하기 위해 두 상관 관계의 차이를 이용할 수 있다.
- \(w_{ij}\)에 대해 visible unit과 hidden unit의 상관관계 <\(v^{0}{i}h^{0}{i}\)>를 측정한다.
- 그런 다음 교대 Gibbs sampling을 수행해 고정 분포에 도달할 때까지 Markov Chain을 실행하고 상관관계 <\(v^{0}{i}h^{0}{i}\)>를 측정한다.
- 훈련 데이터의 로그 확률의 기울기(미분값)은 다음과 같음.(2.1에서 계산된 식 정리한 것)
KL-divergence (Kullback-leibler divergence)
- 두 확률분포의 차이를 계산하는 데에 사용하는 함수.
- 어떤 이상적인 분포에 대해, 그 분포를 근사하는 다른 분포를 사용해 샘플링을 한다면 발생할 수 있는 정보 엔트로피 차이를 계산한다.
- 상대 엔트로피(relative entropy), 정보 획득량(information gain), 인포메이션 다이버전스(information divergence)라고도 한다.
\(H(p, q) = -\sum_{i} p_{i}\ log\ q_{i}\) \(=\ -\sum_{i} p_{i}\ log\ q_{i}\ -\sum_{i} p_{i}\ log\ p_{i}\ +\sum_{i} p_{i}\ log\ p_{i}\) \(=\ H(p)\ +\sum_{i} p_{i}\ log\ p_{i}\ -\sum_{i} p_{i}\ log\ q_{i}\) \(=\ H(p)\ +\sum_{i} p_{i}\ log\ \frac{p_{i}}{q_{i}}\)
- (H(p) : p의 엔트로피)
- p의 엔트로피에 이만큼(\(\sum_{i} p_{i}\ log\ \frac{p_{i}}{q_{i}}\)) 더해진 것이 cross entropy(\(H(p,q)\))가 된다.
- \(\sum_{i} p_{i}\ log\ \frac{p_{i}}{q_{i}}\)가 분포 p와 분포 q의 정보량 차이이다.
- 이 정보량 차이가 KL-divergence.
- KL-divergence는 p와 q의 cross entropy에서 p의 엔트로피를 뺀 값.
- \(KL(p||q)\ = \ H(p,q) - H(p)\)
- \(D_{KL}(p||q)\)로 표기 하기도 함.
KL-divergence의 특성
- \(KL(p|q) >= 0\)
- 0 이상이다.
- \(KL(p|q) != KL(q|p)\)
- KL-divergence는 거리 개념이 아니다.
- asymmetric하다.
KL-divergence와 log likelihood
- 전체를 알 수 없는 분포 p(x) 에서 추출되는 데이터를 우리가 모델링하고 싶다고 가정해보자. 우리는 이 분포에 대해 어떤 학습 가능한 parameter \(\theta\)의 parameter distribution \(q(x|\theta)\)를 이용해 근사 시킨다고 가정해보자.
- 이 \(\theta\)를 결정하는 방법 중 하나는 p(x)와 \(q(x|\theta)\) 사이의 KL-divergence를 최소화시키는 \(\theta\)를 찾는 것이다.
- p(x) 자체를 모르기 때문에 이는 직접 할 수는 없다.
- 하지만 p(x)에서 추출한 샘플 데이터(training set) : (\(x_{n}\))를 알 때 p(x)에 대한 기댓값은 그 샘플들의 평균을 통해 구할 수 있다.
- \(KL(p||q) = \frac{1}{N}\ \sum_{1}^{N} {-ln\ q(x_{n}|\theta) + ln\ p(x_{n})}\)
- ln p(\(x_{n}\))은 \(\theta\) 에 대해 독립이고, \(-ln(q(x_{n}|\theta))\)는 training set으로 얻은 \(q(x|\theta\)) 분포 하에서 \(\theta\)에 대한 negative log likelihood이다.
- 그러므로 KL-divergence를 minimize하는 것이 likelihood를 maximize하는 것과 같다.
- 이 논문에서 대조적 발산 학습(contrastive divergence learning)에서는 두번째 상관 관계를 측정하기 전에 (h 업데이트 후, v 업데이트 하는 각 단계에서) Markov Chain을 실행한다.
- 이 방법은 infinite belief net의 상위 layer에서 나오는 부가효과를 무시한 것인데,
- 이런 무시된 모든 도함수의 합은 \(V_{n}\)층의 사후 분포의 로그 확률의 도함수이다.
- 이는 \(V_{n}\)층의 사후 분포, \(P^{n}_{\theta}\) 및 평형 사이의 KL-divergence의 도함수이기도 하다.
- 따라서 대조 발산 학습은 두 KL-divergence 차이를 최소화한다. \(KL(P^{0}\|\|P^{\infty}_{\theta}) - KL(P^{n}_{\theta}\|\|P^{\infty}_{\theta})\)
- 샘플링 노이즈를 무시하면 위 차이는 결코 음수가 아님.(KL 특징)
- \(P_{\theta}\)는 현재 모델 매개변수에 따라 달라지며 매개변수 변경에 따라 \(P^{n}_{\theta}\)가 변경되는 방식은 대조 발산 학습에서 무시된다는 점에 유의해야 함.
- RBM(제한된 볼츠만 머신)에서의 대조 발산 학습은 매우 효과적이다.
- 실수 단위 다양한 샘플링, 자연 이미지와 생물학적 세포 이미지의 노이즈 제거를 위한 모델링에 매우 성공적이었다.
- 하지만 이 결과들은 많은 비용을 필요로하며, 명백한 방식으로 적용했을때 학습에 실패했다.
- 그래서 RBM과 가중치가 묶인 네트워크 간 동등성이 가중치가 묶이지 않은 다층 네트워크에 대한 효율적인 학습 알고리즘을 제안한다는 것을 보여준다.
4. A greedy learning algorithm for transforming representations
- 복잡한 모델을 학습하는 효율적인 방법은 순차적으로 학습되는 간단한 모델 세트를 결합하는 것.
- 시퀸스의 각 모델이 이전 모델과 다른 것을 학습하도록 강제하기 위해 각 모델이 학습된 후 데이터에 수정이 일어난다.
- boosting : 시퀸스 각 모델은 이전 모델이 잘못된 경우를 강조하는 재가중 데이터에 대해 훈련된다.
- PCA : 모델링된 방향의 분산이 제거되어 다음 모델링된 방향이 직교 부분 공강에 놓인다.
- Projection pursuit(투영 추구) : 데이터 공간의 한 방향을 비선형적으로 왜곡해 해당 방향의 모든 비가우시안성을 제거함으로써(정규분포가 아닌 것 제거) 데이터가 변형됨.
- 그리디 알고리즘의 기본 아이디어는 시퀸스의 각 모델이 데이터의 다른 표현을 수신하도록 허용하는 것.
- 모델은 입력 벡터에 대해 비선형 변환을 수행하고 시퀸스의 다음 모델에 대한 입력으로 사용될 벡터를 출력으로 생성함.
- 이하 설명에서는 가장 단순한 경우를 가정.(모델의 특성 수 동일, 등)
- $W_{0}$를 학습하는 과정은 RBM을 학습하는 작업으로 축소되며, 대조발산을 최소화함으로써 좋은 근사값을 찾을 수 있다.
- $W_{0}$가 학습되면 $W^{T}_{0}$을 통해 데이터를 매핑해 첫 번째 hidden layer에서 더 높은 수준의 데이터를 생성할 수 있다.
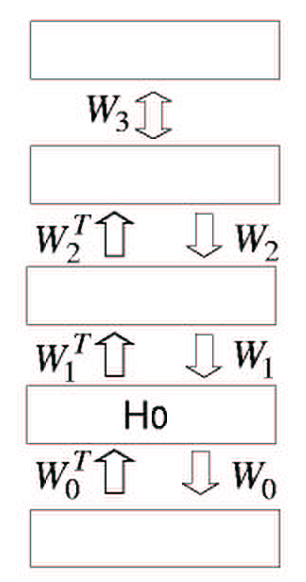
- RBM이 원본 데이터에 대해 완벽한 모델이라 가정한다면 상위 level의 데이터는 이미 상위 level 가중치 행렬에 의해 완벽히 모델링되었을 것이다.
- 그러나 일반적으로 RBM은 원본 데이터를 완벽히 모델링하지 않기 때문에 그리디 알고리즘을 사용해 생성 모델을 더 좋게 만들 수 있다.
- 모든 가중치 행렬이 동일하다고 가정하고 $W_{0}$를 학습한다.
- 각각의 hidden layer를 위한 RBM을 독립적으로 학습하고, 이후 이전 계층의 활성화를 고정시킨 채로 다음 계층을 학습한다. 이는 각각의 hidden layer를 위한 사후 분포를 추론하고자 하는 것.
- 더 높은 가중치 행렬을 모두 서로 연결하고 $W_{0}$에서 연결을 해제한 상태에서 $W^{T}_{0}$를 사용하여 원본 데이터를 변환하여 생성된 상위 수준 데이터의 RBM 모델을 학습한다. => 독립적으로 학습된 hidden layer의 활성화로 visible layer를 재구성(생성)함.
- 각 hidden layer를 최적으로 학습한다는 관점에서 greedy.
- 5페이지하단~6페이지상단 : 이 그리디 알고리즘으로 상위 레벨의 가중치를 변화시키면 생성모델이 개선됨을 보장하는 (Neal and Hinton)의 수학적 증명. - 생략.
5. Back-Fitting with the up-down algorithm
- 이 논문에서 설명한 greedy algorithm은 효율적이지만 최적이 아닐 수 있다.
- 특히 지도학습에서는 라벨이 부족하고 각 라벨이 파라미터에 제한적인 정보를 제공하기 때문에 이런 sub-optimality(greedy algorithm)은 비교적 중요하지 않을 수 있다.
- 반면 비지도학습에서는 각 사례가 매우 고차원일 수 있는데 이러한 경우 언더피팅이 심각한 문제가 될 수 있어, 이전에 학습된 가중치를 수정하는 학습이 필요함.
- 따라서 greedy learning를 통해 각 layer의 가중치에 좋은 초기값을 학습한 후, recognition weights와 generative weights를 분리해, 각 층의 사후분포가 아래층의 변수 값에 대해 조건부 독립이라는 제한을 유지하는 방법이 제안된다.
- 이후 wake-sleep algorithm의 변형을 사용해 높은 수준의 가중치가 낮은 수준의 가중치에 영향을 미칠 수 있도록 해야 한다.
- wake-sleep algorithm : Wake 단계에서는 생성 모델의 파라미터를 업데이트하고, Sleep 단계에서는 이러한 업데이트된 파라미터를 사용하여 모델을 학습.
- Down-pass
- 상위 연관 메모리에서 시작해 top-down 생성 연결을 사용해 확률론적으로 각 하위 layer를 활성화시킴.
- 이 과정동안에는 undirected 연결과 생성 지향 연결은 변경되지 않는다.
- 오직 bottom-up recognition weight만 수정된다.
- 이는 wake-sleep algorithm의 sleep단계와 동일.
- Contrastive form(대조적 형태) : Down-pass를 수행하기 전 up-pass에 의해 연관 메모리가 초기화된 평형 분포에서 샘플링하는 대신 깁스 샘플링을 수행해 생성.
- 대조적 형태는 실제 데이터의 표현에 대해 인식 가중치가 학습되는 것을 보장하고 Mod Average문제를 제거하는데 도움이 된다.