FixBi-Bridging Domain Spaces for Unsupervised Domain Adaptation [논문]
저자 : Wonjun Hwang
1. Introduction
최근 컴퓨터 비전 딥러닝 애플리케이션에서 상당한 개선을 보였지만, 대부분 지도학습이었다. 지도학습에는 데이터를 수입하는데 많은 비용이 들어 준지도(semi-supervised), 비지도(unsupervised)학습이 연구되었는데 이는 유사한 도메인에서의 학습이었다.
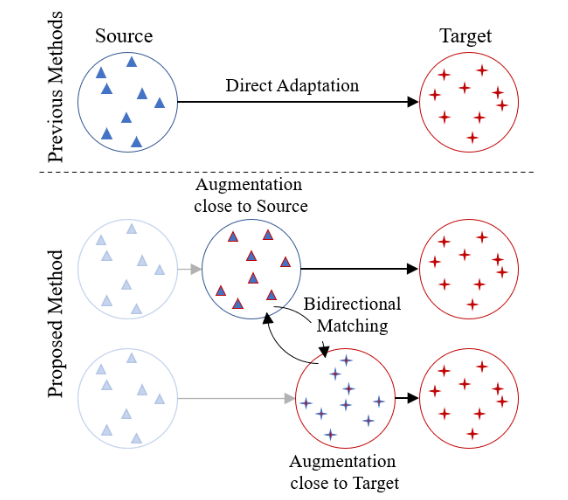
이전 UDA에서는 source와 target 도메인의 격차를 줄이기 위해 discriminator(판별자), MMD, JMMD 등을 사용했고 GAN 기반 DA가 사용되었다. 기본적으로 이는 source와 target간의 거리가 큰 경우는 고려되지 않는다.
이 논문에서는 큰 도메인 불일치를 효율적으로 보상하기 위해 서로 상보적인 중간 증강 도메인을 구성한다. 이를 위해 Fixed ratio based mixup을 제안한다.
Fixed ratio based mixup은 source와 target사이 무작위성을 최소화하고 여러 중간 도메인을 생성한다.
예를들어 Augmented domain close to the source domain 은 레이블 정보는 있지만 target 도메인과 상관관계는 낮다.
반면 Augmented domain close to the target domain은 라벨 정보는 부정확하지만 target domain과 유사성은 높다.
이런 증강된 도메인에서 source와 target 도메인 사이를 연결하도록 서로 가르치는 보완모델을 훈련한다. 구체적으로, target 샘플에 대한 높은 신뢰도 예측을 기반으로 한 양방향 매칭을 도입해 중간 도메인을 target 도메인으로 연결시킨다.
또한 self-traning을 통해 성능을 향상시키기 위해, self-penalization을 적용한다.
또한 각 iteration마다 변화하는 특성을 적절히 부과하가 위해 각 미니배치의 신뢰분포에 의한 적응형 임계값을 사용한다.
마지막으로 서로 다른 증강된 모델의 발산을 막고자, source와 target 샘플의 비율이 동일한 증강 도메인을 사용해 일관성 정규화를 제안한다.
Office-31, Office-Home, VisDA에서 테스트를 수행했다.
2. Related Work
semi supervised learning(준지도 학습)
- 레이블 부족 문제 개선
- 데이터 증강 기반 최근 연구 활발 (MixMatch, FixMatch, ReMixMatch 등)
MixMatch: 데이터 증강, 엔트로피 최소화
FixMatch: 일관성 정규화, 의사 레이블, 강화된 증강
ReMixMatch: MixMatch + FixMatch + 분포 일치 손실 + 자동 증강
- 주로 레이블/레이블되지 않은 데이터가 유사 도메인 가정
SSDA(semi supervised domain adaptation)에 비해 UDA는 더 많은 target lable의 정보를 가지고 있다.
semi supervised의 신호를 활용한 연구
[Semi-supervised domain adaptation via minimax entropy] : 적응적 few-shot 모델 최적화를 위한 minimax 엔트로피 접근 [Opposite structure learning for semi-supervised domain adaptation] : 생성기와 두 개의 분류기를 이용하여 반대 구조 학습 통합
[Mixup co-training for semi-supervised domain adaptation. - 44] 과 본 논문 비교.
- [44]에서는 SSDA를 SSL과 UDA로 분류하여 해결하고자 함.
- 두 가지 모델이 각 하위 문제를 담당하며 co-training 기반으로 학습.
- 한 모델은 labeled source sample 과 labeled target sample로 훈련됨.
- 다른 한 모델은 unlabeled target sample과 labeled target sample로 훈련됨.
반면 ([44]와 다르게) 이 논문에서는 양방향 매칭을 통해 target 도메인의 의사 레이블을 훈련한다. 또한 [44]에서는 일부 target sample을 선택 사용하지만 본 논문에서는 모든 target sample을 사용한다.
최근 여러 연구에서는 도메인 정렬 및 차별적인 도메인 불변적 특성 학습 방법을 기반으로 UDA에 중점을 두고 있다.
- Deep Adaptation Network(DAN)은 도메인 특정 계층에 대한 MMD를 최소화하고 Joint Adaptation Network는 JMMD를 기반으로 여러 도메인에 걸쳐 도메인 특정 레이어의 공동 분포를 정렬했습니다.
- Deep Domain Confusion(DDC)는 discriminative 도메인과 transferable 도메인을 모두 학습시키기 위해 fully connected layer에서 MMD metric을 사용했다.
- Domain Adversarial Neural Network(DANN)은 도메인 분류기의 reverse gradients를 back-propagating해 도메인 불변 표현을 학습했다.
- Adversarial Discriminative Domain Adaptation(ADDA)는 source label을 사용하여 판별적 표현을 학습한 후 도메인-적대 손실을 기반으로 대상 데이터를 동일한 공간에 매핑하는 별도의 인코딩을 사용한다.
- Maximum classification discrepancy(MCD)는 대상 샘플의 불일치를 최대화한 다음 이 불일치를 최소화하는 기능을 생성하여 작업별 결정 경계를 고려하여 대상 도메인의 분포를 정렬하려고 했다.
- Contrastive adaptation network(CAN)는 클래스 내 도메인 불일치와 클래스 간 도메인 불일치를 명시적으로 모델링하는 도메인 불일치를 최소화하기 위한 metric을 최적화했다.
- Robust spherical domain adaptation(RSDA)는 구형 분류기와 구형 도메인 구별기를 사용하여 레이블 예측과 도메인 구별을 수행하며, 구형 특징 공간에서 강인한 의사 레이블 손실을 활용한다.
- Structurally regularized deep clustering(SRDC) 중간 네트워크 특징을 군집화하고 source example 선택의 구조적 정규화를 통해 target 식별을 개선합니다.
- Dual mixup regularized learning(DMRL) 샘플 간 일관적인 예측 향상과 잠재 공간의 내재 구조 강화를 위해 분류기를 유도합니다. 소스와 타겟 도메인 혼합을 위해 랜덤성 기반 믹스업 정규화 두 가지를 제안합니다.
본 연구에서는 기존 연구 ([41, 43] 등)과 달리 랜덤성에만 의존하여 증강 도메인을 생성하지 않는다. 대신 두 개의 Fixed ratio mixup을 사용해 두 가지 증강 도메인을 생성한다.
- source closed augmented domain : 명확한 label 존재, target domain과는 거리가 있음.
- target closed augmented domain : target domain 특성 존재, source domain과는 거리가 있음.
서로 다른 특징을 가진 두 증강 도메인을 사용하여 서로 “가르치는” 방식으로 학습 이를 통해 도메인 지식을 타겟 도메인으로 효과적으로 전달
3. Proposed methods
UDA에서는 source 도메인으로부터 label이 지정된 데이터 \( X^{s} = {(x_i^s, y_i^s)}^{N_s}_{i=1}\) 가 주어지고,
target 도메인으로부터 label이 지정되지 않은 데이터 \( X^{t} = {(x_i^t)}^{N_t}_{i=1}\) 가 주어진다.
Ns와 Nt는 각각 Xs와 Xt의 크기를 나타낸다. 이 논문의 목표는 source 도메인에서 학습한 지식이 target 도메인에서 잘 일반화되도록 하는 것이다.
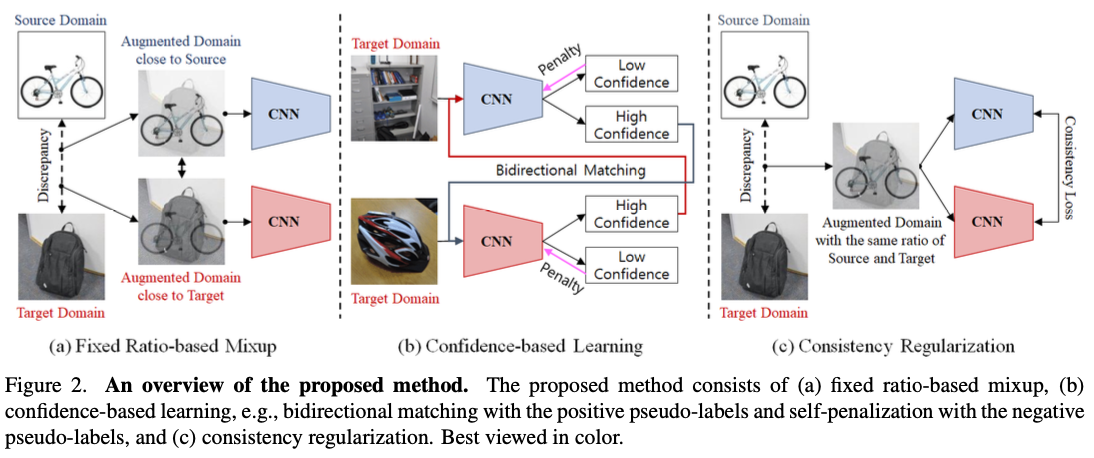
3.1 Fixed Ratio-based Mixup
기존 믹스업의 문제점:
- 기존 믹스업에서는 랜덤하게 생성된 비율로 source 데이터와 target 데이터를 혼합하여 가상 샘플을 생성한다.
- 이는 도메인 간 격차를 고려하지 않고 가상 샘플을 만드기 때문에 모델 성능 향상에 한계가 있다.
제안된 고정 비율 믹스업:
- 본 논문에서는 랜덤 비율 대신 고정 비율 (λsd, λtd)을 사용하여 가상 샘플을 생성한다.
- 이 고정 비율은 source 데이터와 target 데이터의 중요도를 반영한다.
- 또한 두 개의 다른 믹스업 비율을 사용하여 source 우세 모델 (SDM)과 target 우세 모델 (TDM)이라는 두 가지 네트워크를 생성한다.
- SDM은 source 데이터에 더 강한 영향을 받아 학습되고, TDM은 target 데이터에 더 강한 영향을 받아 학습된다.
입력 샘플 쌍과 source 및 target 도메인의 해당 one-hot labels\( (x^s_i, y_i^s) \)이 주어지면 mixup setting은 다음과 같이 정의됩니다:
\[\widetilde{x}^{st}_i = \lambda x^{s}_i + (1-\lambda)x^{t}_i\] \[\widetilde{y}^{st}_i = \lambda y^{s}_i + (1-\lambda)\hat{y}^{t}_i\]그리고 \(p(y\| \widetilde{x}^{st}_i)\)를 입력 \(\widetilde{x}^{st}_i\)에 대한 모델에 의해 생성된 예측된 클래스 분포라고 하자. 그러면 fixed ratio-based mixip은 다음과 같이 정의된다.
\[L_{fm} = \frac{1}{B} \sum_{i=1}^{B} \widetilde{y}^{st}_i log(p(y\\| \widetilde{x}^{st}_i))\]3.2 Confidence-based learning
상호 보완 학습:
- 고정 비율 믹스업으로 생성된 두 모델은 서로 다른 특징을 가지고 학습된다.
- 이러한 서로 다른 특징은 서로 보완적인 학습을 가능하게 한다.
신뢰도 기반 학습:
- 한 모델은 긍정적 의사 라벨을 사용하여 다른 모델을 가르치고, 부정적 의사 라벨을 사용하여 자기 자신을 학습한다.
양방향 매칭:
- 모델 중 하나가 특정 임계값 이상의 확률로 클래스를 예측하면 이를 긍정적 의사 라벨로 사용한다.
- 긍정적 의사 라벨을 이용하여 서로 다른 모델의 예측이 일치하도록 학습한다.
self penalization:
- 부정적 의사 라벨 (확률 낮은 최고 예측 클래스)을 사용하여 각 모델이 예측 오류를 줄이도록 학습한다.
낮은 확률 예측 활용:
- 일반적으로 낮은 확률 예측은 신뢰성이 낮으나, 이 논문에서는 이러한 예측도 학습에 활용한다.
적응적 임계값:
- 긍정적/부정적 의사 라벨을 구분하는 임계값을 고정 값 대신 미니배치 데이터의 평균과 표준편차를 이용하여 동적으로 조정한다.
3.3 Consistency Regularization
신뢰도 기반 학습을 통해 더 정확한 의사 라벨을 가지고 학습함으로써 두 모델이 target 영역에 더 가까워진다. 새로운 일치성 정규화는 두 모델 모두 안정적으로 수렴하도록 한다. 잘 학습된 모델은 같은 공간에서 일관된 결과를 보여야 한다는 가정을 기반으로 한다. 이는 서로 다른 도메인에서 학습된 두 모델이 source와 target 도메인 사이의 중간 공간에서 일관성을 유지하도록 하여 도메인 간 연결을 구축한다. 중간 공간에서는 고정 믹스업 비율 λsd와 λtd가 모두 0.5로 설정된다. 일치성 정규화 손실 함수는 다음과 같이 정의된다.
\[L_{cr} = \frac{1}{B} \sum_{i=1}^{B} || p(y\\| \widetilde{x}^{st}_i) - q(y\\| \widetilde{x}^{st}_i) ||^{2}_2\]